Problem 1: "I am all the time checking a website for an agenda or announcement!"
Solution: Maybe a robot can check it.
Changedetection.com will email you if a page changes. It checks about once a day, I think.
IFTTT.com can check Twitter, RSS feeds, Reddit and other data streams and send you an email, Tweet, add a line to a Google spreadsheet, etc when it gets something of interest.
Can robots check other social media like FB, Instagram?
As far as I know, no publicly-available robot will check other people's traffic on these two. But see Problem 2 for some advanced searches.
But anyway, while I'm standing here, let's do an IFTTT recipe that will send me an email each time there's a USDOJ press release about Georgia.
It's the same as in this video, so you can watch later if you like.
Can robots check other social media like FB, Instagram?
As far as I know, no publicly-available robot will check other people's traffic on these two. But see Problem 2 for some advanced searches.
But anyway, while I'm standing here, let's do an IFTTT recipe that will send me an email each time there's a USDOJ press release about Georgia.
It's the same as in this video, so you can watch later if you like.
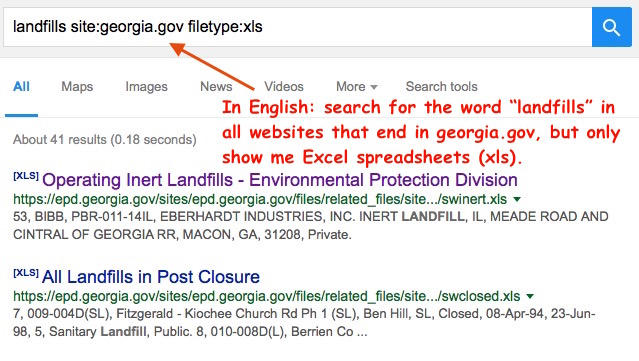
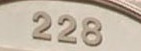 . Text is like this: 228
. Text is like this: 228